Reference
1. Bagging
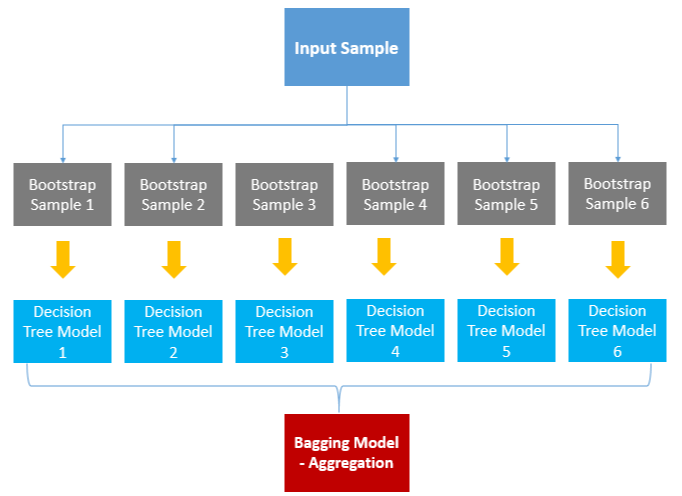
- Bagging은 여러 bootstrap으로 각 모델을 학습시켜 집계하는 방법이다.
- bootstrap은 random sampling하여 만든 훈련 데이터셋의 서브셋이다(표본).
- Bagging의 한 가지 방법으로 estimate의 분산을 줄이기 위해 여러 estimate의 평균을 구하는 방법이 있다.
- \(f(x) = \cfrac{1}{M} \sum\limits_{m=1}^{M} f_m(x)\)
- base learners 결과값을 집계하는 방식은 다음과 같다.
- classification의 경우, 투표를 통해 집계한다.
- regression의 경우, 평균을 계산하여 집계한다.
- ex) Random Forest
2. Random Forest
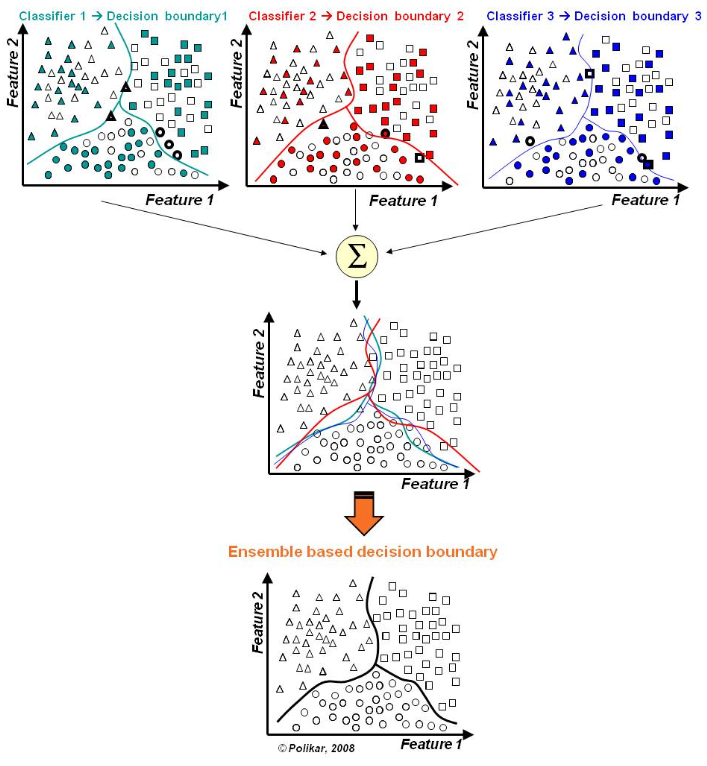
- 주로 사용하는 bagging 모델로 Random Forest가 있다.
- N개의 bootstrap sample 별로 만들어진 tree 모델들을 ensembles 한 것이다.
- 랜덤성에 의해 tree들이 서로 조금씩 다르게 만들어 진다.
- forest의 bias가 약간 증가하지만, 여러 tree의 평균 연산으로 노이즈에 대한 민감함이 감소했기때문에 variance는 감소된다.
- 특정 feature가 모델에 많은 영향을 줄 때, 모든 tree의 결과가 비슷하다.
- 대부분의 tree가 같은 feature를 사용하기 때문이다.
- 따라서, tree correlation이 높아진다
(bagging은 base learners간 상관관계를 고려하지 않다는 문제점을 가지고 있다).
- tree가 비슷하게 만들어지면, variance가 감소되지 않는다.
- tree correlation 문제를 해결하기 위해 데이터 sampling 시 feature도 random으로 선택한다.
- 모든 tree가 서로 다른 데이터셋과 feature로 학습하게 된다.
- 따라서, tree correlation이 줄어든다.