Reference
- 핸즈온 머신러닝 / 오렐리앙 제롱 / 박해선
- 파이썬 라이브러리를 활용한 머신러닝 / 안드레아스 뭘러, 세라 가이도 / 박해선
- 케라스 창시자에게 배우는 딥러닝 / 프랑소와 숄레 / 박해선
- 지도학습, 비지도학습, 강화학습
1. 머신러닝(Machine Learning)이란
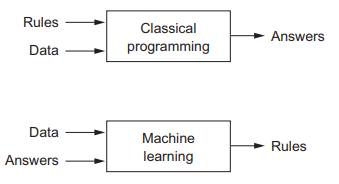
- 머신러닝이란 (명시적인 프로그래밍 없이) 기계가 데이터로부터 학습하여 어떤 작업을 더 잘하도록 만드는 것이다.
- 즉, 머신러닝은 입력 데이터를 기반으로 기대 출력에 가깝게 만드는 유용한 표현을 학습한다.
- 학습이란 더 나은 표현을 찾는 자동화된 과정이다.
준비물
- 입력 데이터
- 기대 출력(Target)
- 알고리즘 성능 측정 방법
- 알고리즘의 현재 출력과 기대 출력 간의 차이를 결정하기 위해 필요하다.
- 측정값은 알고리즘의 작동 방식을 교정하기 위한 신호로 다시 피드백된다. \(\to\) 학습
- 전통적인 프로그래밍 기법으로는 너무 복잡할 때 유용하다.
- 전통적인 접근법으로는 문제가 단순하지 않아 규칙이 점점 길고 복잡해져 유지 보수가 힘들어진다.
- 반면 머신러닝 기법은 데이터로부터 스스로 학습하기 때문에 유지 보수가 쉽다.
- 머신러닝 알고리즘이 학습한 것을 조사하여 예상치 못한 연관 관계나 새로운 추세를 발견할 수 있다.
- 머신러닝 기술을 적용해서 대용량의 데이터를 분석하면 겉으로는 보이지 않던 패턴을 발견할 수 있다. \(\to\) Data Mining
2. 머신러닝 시스템의 종류
- 지도 학습(Supervised Learning)
- 훈련 데이터에 레이블(Label)이라는 원하는 답이 포함되어, 레이블에 입력 데이터를 매핑하는 방법을 학습한다.
- 분류(Classification) : 미리 정의된, 가능성 있는 여러 클래스 레이블 중 하나를 예측하는 것
- 회귀(Regression) : 연속적인 숫자(실수)를 예측하는 것
- K-Nearest Neighbors, Linear Regression, Logistic Regression, Support Vector Machine, …
- 비지도 학습(Unsupervised Learning)
- 훈련 데이터에 레이블이 없으며, 입력 데이터에 대한 흥미로운 변환을 찾는다.
- 데이터 시각화, 데이터 압축, 데이터의 노이즈 제거 또는 데이터에 있는 상관관계를 더 잘 이해하기 위해 사용한다.
- Clustering, Visualization, Dimensionality Reduction, Association Rule Learning, …
- 준지도 학습(Semisupervised Learning)
- 레이블이 일부만 있는 훈련 데이터를 가지고 학습한다.
- 강화 학습(Reinforcement Learning)
- 에이전트(학습하는 시스템)가 환경을 관찰하여 행동을 실행하고 그 결과로 보상 또는 벌점을 받는다.
- 시간이 지나면서 가장 큰 보상을 얻기 위해 정책(최상의 전략)을 스스로 학습한다.
- 정책은 주어진 상황에서 에이전트가 어떤 행동을 선택해야 할지 정의한다.
3. 머신러닝에서 자주 발생하는 데이터 문제
- 충분하지 않은 양의 훈련 데이터
- 대부분의 머신러닝 알고리즘은 잘 작동하려면 데이터가 많아야 한다.
- 아주 간단한 문제에서조차도 많은 데이터가 필요하다.
- 대표성 없는 훈련 데이터
- 일반화가 잘되려면 일반화하기 원하는 새로운 사례를 훈련 데이터가 잘 대표해야 한다.
- 샘플이 작으면 우연에 의한 대표성 없는 데이터가 생긴다. \(\to\) 샘플링 잡음(Sampling Noise)
- 매우 큰 샘플도 표본 추출 방법이 잘못되면 대표성을 띠지 못할 수 있다. \(\to\) 샘플링 편향(Sampling Bias)
- 낮은 품질의 데이터
- 훈련 데이터가 에러, 이상치, 잡음으로 가득하다면 머신러닝 시스템이 내재된 패턴을 찾기 어려워 잘 작동하지 않는다.
- 그래서 훈련 데이터 정제에 많은 시간을 들인다.
- 관련 없는 특성
- 훈련 데이터에 관련 없는 특성이 적고 관련 있는 특성이 충분해야 시스템이 학습할 수 있다.
- 성공적인 머신러닝 프로젝트의 핵심 요소는 훈련에 사용할 좋은 특성을 찾는 것이다. \(\to\) 특성공학(Feature Engineering)
- 특성 선택(Feature Selection) : 가지고 있는 특성 중에서 훈련에 가장 유용한 특성 선택
- 특성 추출(Feature Extraction) : 특성을 결합하여 더 유용한 특성 생성
- 새로운 데이터를 수집해 새 특성 생성
- 훈련 데이터 과대적합
- 모델이 훈련 데이터에 너무 잘 맞지만 일반성이 떨어질 수 있다.
- 복잡한 모델은 데이터의 미묘한 패턴을 감지할 수 있지만, 훈련 세트에 잡음이 많거나 데이터셋이 적으면 잡음이 섞인 패턴을 감지한다. 이런 패턴은 새로운 샘플에 일반화되지 못한다. \(\to\) 과대적합(Overfitting)
- 과대적합은 훈련 데이터에 있는 잡음의 양에 비해 모델이 너무 복잡할 때 일어난다.
해결방법
- 파라미터 수가 적은 모델을 선택하거나, 훈련 데이터에 있는 특성 수를 줄이거나, 모델에 제약을 가하여 단순화시킨다.
- 훈련 데이터를 더 많이 모은다.
- 훈련 데이터의 잡음을 줄인다.
- 훈련 데이터 과소적합
- 모델이 너무 단순해서 데이터의 내재된 구조를 학습하지 못하는 경우가 있다. \(\to\) 과소적합(Underfitting)
해결방법
- 모델 파라미터가 더 많은 강력한 모델을 선택한다.
- 학습 알고리즘에 더 좋은 특성을 제공한다(특성공학).
- 모델의 제약을 줄인다.
4. 머신러닝 모델 평가
- 머신러닝의 목표는 처음 본 데이터에서 잘 작동하는 일반화된 모델을 얻는 것이다.
- 모델의 일반화 성능에 대한 신뢰할 수 있는 측정 방법은 중요하다.
- 모델 평가의 핵심은 가용한 데이터를 항상 훈련, 검증, 테스트 3개의 셋으로 나누는 것이다.
- 훈련셋 : 모델 훈련
- 검증셋 : 모델 평가
- 테스트셋 : 최종적으로 한 번 테스트
- 테스트셋으로 모델을 평가하면 안된다.
5. 보편적인 머신러닝 작업 흐름
-
문제 정의와 데이터셋 수집
-
성능 측정 지표 선택
-
평가 방법 선택
- 데이터 준비
-
모델 선택과 훈련
-
모델 세부 튜닝
- 론칭, 모니터링, 시스템 유지 보수