Reference
- 패턴 인식과 머신 러닝 (PATTERN RECOGNITION AND MACHINE LEARNING) / 크리스토퍼 비숍 지음 / 김형진 옮김
- 패턴 인식은 컴퓨터 알고리즘을 활용하여 데이터의 규칙성을 자동적으로 찾아낸다.
- 그리고 이 규칙성을 이용하여 데이터를 각각의 카테고리로 분류하는 등의 일을 한다.
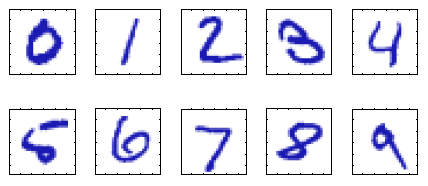
- 손글씨로 쓰인 숫자를 인식하는 예시를 살펴보자.
- 각 숫자는 28 X 28 픽셀 이미지이며, 784개의 실수로 구성된 벡터로 표현할 수 있다.
- 목표는 이 벡터 \(x\)를 입력값으로 받았을 때 숫자 0~9 중 하나의 값을 올바르게 출력하는 기계를 만드는 것이다.
- 필체의 모양을 바탕으로 직접 작성한 규칙으로 이 문제를 해결하려 시도할 수 있다.
- 하지만 수많은 규칙이 요구되며, 각각의 규칙에 예외 사항을 만드는 등 끊임없이 수 많은 룰을 만들어야 한다.
- 결국 좋은 성능을 얻지 못한다.
- 머신 러닝을 적용하면 훨씬 더 나은 결과를 얻을 수 있다.
- 일단 \(N\)개의 숫자들 \(\{ x_1, \cdots , x_N \}\)을 훈련 집합(training set)으로 정의한다.
- 각 숫자의 카테고리를 표적 벡터(target vector) \(t\)로 표현해보자.
- 각각의 숫자 이미지 \(x\)에 대한 표적 벡터 \(t\)는 하나이다.
- 이 훈련 집합으로 변경 가능한 모델의 매개변수들을 조절하는 방식으로 학습한다.
- 머신 러닝 알고리즘의 결과물은 함수 \(y(x)\)로 표현할 수 있다.
- \(y(x)\)는 새로운 숫자의 이미지 \(x\)를 입력값으로 받았을 때 대상 벡터와 같은 방식으로 부호화된 벡터 \(y\)를 출력하는 함수이다.
- 한 번 훈련되고 난 모델은 새로운 숫자 이미지들인 시험 집합(test set)을 활용하여 성능을 평가할 수 있다.
- 훈련 단계에서 사용되지 않았던 새로운 예시들을 올바르게 분류하는 능력을 일반화(generalization) 성능이라고 한다.
- 패턴 인식에서 가장 중요한 목표중 하나는 일반화이다.
- 원래 입력 변수들을 전처리(preprocessed)하여 새로운 변수 공간으로 전환할 수 있다.
- 패턴 인식 문제를 더 쉽게 해결할 수 있다.
- 특징 추출(feature extraction), 차원 감소(dimensionality reduction)
- 훈련 집합에서 사용한 것과 같은 전처리 과정을 시험 집합에도 동일하게 적용해야 한다.
- 주어진 훈련 데이터가 입력 벡터와 그에 해당하는 표적 벡터로 이루어지는 문제들을 지도 학습(supervised learning) 문제라고 한다.
- 표적 벡터가 제한된 카테고리 중 하나에 할당되는 경우에는 분류(classification) 문제라고 한다.
- 기대되는 출력값이 하나 또는 그 이상의 연속된 값일 경우에는 회귀(regression) 문제라고 한다.
- 훈련 데이터가 해당 표적 벡터 없이 오직 입력 벡터 \(x\)로만 주어지는 경우의 패턴 인식 문제는 비지도 학습(unsupervised learning) 문제라고 한다.
- 데이터 내에서 비슷한 예시들의 집단을 찾는 집단화(clustering) 문제
- 입력 공간에서의 데이터 분포를 찾는 밀도 추정(density estimation) 문제
- 높은 차원의 데이터를 이차원 또는 삼차원에 투영하여 이해하기 쉽게 만들어 보여주는 시각화(visualization)
- etc.
- 강화 학습(reinforcement learning)은 주어진 상황에서 보상을 최대화하기 위한 행동을 찾는 문제를 푸는 방법이다.
- 각각의 알고리즘을 해결하는 데는 서로 다른 방법과 기술이 필요하다.
- 이 장에서는 예시를 통해 문제를 해결하는 핵심 아이디어들에 대해 간단히 알아보자.
- 앞으로의 내용에서 필요한 세 가지의 중요한 도구인 확률론, 의사 결정 이론, 정보 이론에 대해 알아보자.